
Outils informatiques pour les sciences du langage, comment en choisir un ?
Vous êtes novice en sciences du langage, cet article que propose Dr Inoussa Guiré, jeune chercheur de l’Institut des sciences des sociétés (INSS), va vous vous intéresser. Il vous donne des informations sur certains outils informatiques destinés à faciliter la collecte, le traitement et l’analyse des données de recherche basée sur le texte ou sur l’oral. Il est assorti de quelques conseils de bon choix.
L’envie de décrire et de formaliser avec plus de précision oblige les chercheurs à se tourner vers l’informatique afin de se faciliter la tâche. Dans presque tous les domaines des sciences du langage, le recours aux outils informatiques devient de plus en plus nécessaire. De leur côté, les informaticiens sont permanemment interpellés pour le développement des logiciels afin de répondre aux sollicitations du monde de la recherche et des entreprises. En plus de cette collaboration, les chercheurs de différents laboratoires et unités de recherches s’associent pour mieux orienter les outils informatiques dans leurs travaux.
Cet article tient à vulgariser un certain nombre d’outils informatiques spécifiques pour un meilleur choix. La méthodologie a consisté à recenser ceux que nous avons appris, utilisés ou expérimentés dans notre cursus de recherche en sciences du langage. Certains ont été utilisés dans le traitement et l’analyse de données de recherche. C’est le cas de Toolbox en sémantique lexicale en 2006 (Guiré, 2007), Praat en acoustique de la parole (guiré 2012), CLAN en traitement et analyse de corpus multimédias bilingue (guiré 2015).
D’autres ont été appris ou expérimentés lors des stages de Formation et dans des projets de recherche. Il s’agit de Nooj appris en février 2012 à l’INALCO à Paris, Flex à la SIL de Ouagadougou en 2014, Sphinx IQ et Cmap Tools dans les projets TRANSLANGA (transmission des langues en Afrique subsahariennes) et AREN (Alliance pour la recherche en Education numérique) en 2016. D’autres encore ont constitué des unités d’enseignements que nous avons validées. Il s’agit du langage XML/XSLT, des expressions régulières de Awk et de Perl pour structurer et manipuler les données texte, LaTex pour la rédaction des documents scientifiques…
Le choix n’est pas facile, surtout lorsque l’on fait ses premiers pas dans la recherche, alors qu’il faut être capable de justifier la pertinence de l’outil qu’on a choisi pour sa méthodologie. Avant de donner des conseils pour un bon choix d’outils informatiques pour la recherche, il importe de revenir sur les options de transcriptions et aussi sur les fonctionnalités de quelques-uns de ces logiciels en sciences du langage.
On note avec Cetro (2011) que certains outils informatiques pour la linguistique adoptent une approche statistique comme SPSS, d’autres un approche linguistique et d’autres encore une approche dite hybride. L’approche statistique vise à exploiter de gros corpus mais ne met pas l’accès sur le qualitatif lié à l’énonciation. Les logiciels qui utilisent l’approche linguistique sont ceux qui sont conçus dès la base sur des critères de recherches linguistiques, voire, sur des théories linguistiques. Ils incluent une description linguistique fine du phénomène étudié avec l’avantage de traiter même les corpus de petite taille. Ils permettent ainsi les traitements lexical, morphologique et syntaxique.
En terminologie par exemple, le tout premier en contexte francophone semble être le progiciel Termino qui est devenu Nomino. Il est « développé par S. David et P. Plante en 1990, dans le cadre d’une collaboration entre l’Office de la Langue Française du Québec et l’Université du Québec à Montréal » Il était destiné à « repérer dans un corpus les unités nominales syntaxiques susceptibles de se lexicaliser (suivant la théorie des synapsies de Benveniste) ». (Cetro, 2011, p.53). Dans le même domaine, on a des logiciels comme Lexter développé par D. Bourigault en 1993 au compte de Électricité De France (EDF) pour l’extraction et la structuration terminologique, Terminology Extractor développé par Etienne Cornu au compte de l’entreprise Chamblon Systems Inc. Cambridge (Ontario, Canada) et destiné à l’extraction terminologique. Ensuite, vient la phase des logiciels hybriques qui ont l’avantage de cumuler le traitement linguistique et statistique visant à faciliter à la fois les recherches quantité et la qualité. De nos jours, ce sont ces logiciels qui sont les plus en vue.
Mais la réalité actuelle de l’utilisation des outils informatiques pour la recherche va au-delà de ce classement de Cetro (2011). Certains logiciels, en plus d’être hybrides, sont employés dans plus d’une discipline. Il s’agit par exemple de Tropes qui est initialement conçu pour l’analyse sémantique. Mais il est utilisé dans d’autres disciplines comme en science de l’information, en markéting, en sciences politiques, en sciences de l’éducation, en psychologie et même en intelligence économique comme outil de veille concurrentiel. C’est aussi le cas de Nooj qui est initialement conçu par et pour les linguistes. Mais son auteur, le professeur Max Silberztein, nous confiait lors du stage de formation intensive en début février 2012 qu’il animait à l’INALCO à Paris, que son logiciel est utilisé en intelligence économique et sollicité dans bien d’autres domaines. Aussi, le logiciel Sphinx iQ destiné aux enquêtes qualitatives et quantitatives de façon générale prévoit en « option Quali », l’analyse textuelle et sémantique. Et pour avoir cette option, il faut rentrer en contact avec le service commercial de ce logiciel pour une licence supplémentaire. Et la liste est longue et continue de s’allonger.
Tous ces logiciels utilisent des données textuelles, alors que beaucoup de nos recherches en Afrique ont recours à la tradition orale. Le recueil de corpus audio et vidéo s’avère nécessaire. Il faut pour cela, une autre catégorie de logiciels capables de traiter scientifiquement ce type de données. Ce traitement passe d’abord par la maîtrise des normes de transcriptions.
1.1. La transcription des données
Il est reconnu qu’il est presque impossible d’exploiter directement un enregistrement sonore ou visuel à partir du seul fait de réécouter. « On ne peut pas étudier l’oral par l’oral en se fiant à la mémoire qu’on en garde. On ne peut pas sans le secours de la représentation visuelle, parcourir l’oral en tous sens et en comparer les morceaux » (Blanche-Benveniste, 2000, p. 24). Il est nécessaire d’avoir une phase dédiée à la transcription de l’enregistrement avant son exploitation. Les outils informatiques pour la linguistique proposent des conventions de transcription pour assurer l’extraction aisée des données. En plus de ces conventions, certaines langues orales, selon les pays, doivent être transcrites avec un alphabet qui ne pas forcément celui de l’Alphabet Phonétique International (API). Ce n’est donc pas une transcription phonétique qui y est utilisée.
La transcription est destinée à faciliter l’analyse et non pas à la remplacer. Les linguistiques ont adopté une convention de transcription pour les langues africaines au regard de leur statut de langue orales. Il s’agit de l’IAI (International African Institute). Au Burkina Faso par exemple, un alphabet orthographique a été adopté pour toutes les langues nationales. C’est au vue de cet alphabet orthographique national que les sous-commissions nationales des langues adoptent un alphabet et des règles orthographiques pour chaque langue. A partir de ce moment, tout travail qui se fera sur une langue quelconque du pays doit se faire selon ces règles orthographiques codifiées. Cette transcription est graphémique et non phonémique.
Il y a plusieurs types de transcriptions ;
1.2. La transcription des entretiens pour un rendu simple
Beaucoup de structures ont recours à des enquêtes auprès des populations pour diverses raisons. Au niveau des sciences de la santé par exemple, pour ne prendre que cet exemple, des méthodes et des outils sont souvent mis en expérimentation. Et le ressenti de la population est requis pour l’évaluation de ces pratiques. Ainsi, des études sont commanditées et des enquêtes sont menées soit au niveau de la population bénéficiaire, soit au niveau des praticiens que sont les médecins, les infirmiers, les sages-femmes.
Les enquêtes réalisées auprès des populations lettrées sont transcrites directement en français. Dans ce type de transcription, la tâche consiste simplement à écouter et à écrire ce que l’on entend. La spécificité réside au niveau du fait que le transcripteur doit savoir omettre les partie inutiles comme les hésitations, les reprises et reformulation pour ne garder que le contenu des idées développées, toutes et rien que les informations et idées importantes. Ce qui est attendu de ces transcriptions, c’est le rendu plus ou moins exact du contenu de la parole.
1.3. La transcription pour la recherche en sciences du langage
Ce type de transcription à deux objectifs à savoir, automatiser la fouille, l’extraction et le partage des données, et orienter la recherche sur la langue. Ce pourrait être des recherches en sociolinguistique, en didactique des langues, en psycholinguistique ou en linguistique descriptive. La transcription à usage scientifique est une tâche fastidieuse. Mais lorsqu’elle est soigneusement faite, elle permet toutes sortes de manipulation du contenu linguistique transcrit en la rendant exploitable.
Pour les dictionnaires, on peut citer Toolbox né de Shoobox, et Linguae que nous nous utilisons depuis 2006 dans le cadre du Koromfe langue du Nord du Burkina, qui est en train d’être remplacé par FleX. Il faut rappeler que presque tous les membres du département de linguistique et des langues Nationales de l’institut des sciences des Sociétés ont été initiés à FleX.
2. Les outils informatiques pour les sciences du langage
La caractéristique des outils informatiques pour la linguistique dans le traitement des corpus oraux est qu’ils permettent d’avoir à la fois le son et sa transcription correspondante. Le son ou l’image sonore peut être segmenté en énoncés ou en unités syntaxiques ou lexicales. Selon les logiciels, on peut même affiner la segmentation afin de transcrire les unités linguistiques plus petites au niveau acoustique. On peut citer entre autres outils linguistiques pour la transcription et le traitement des corpus oraux, ELAN, TRANSANA, Transcriber, EXAMARaLDA, ANVIL, CLAN, Praat…
ELAN (Educo Linguistic Annotation) est un logiciel de transcription de fichiers audio (en wav) et vidéo (en mpeg1-2 et mov, avi, wmv) créé initialement par Birgit Hellwig. En plus de ses tiers ou pistes d’annotations qui peuvent être multiples et hiérarchiquement interconnectées, il contient une zone d’oscillogramme de forme sonore. Selon le tutoriel ELAN version 2009 , la transcription dans ELAN est conservée au format XML, ce qui est très utile pour la gestion des métadonnées, mais cela n’est pas à la portée de tous. Contrairement à TRANSANA, ELAN est un logiciel freeware qui fonctionne sur Macintosh, Windows et Linux .
Transana est aussi un logiciel d’analyse des données audio en mp3, wav, wma et mov et vidéo en mpeg 1 et 2, avi et mov. Il est créé par Chris Fassnacht et fonctionne sur Macintosh et Windows. Il prend également en entrée des fichiers texte en format rtf. Le format d’exportation des données de Transana est en XML (.xml). Il permet d’avoir dans une même fenêtre la vidéo ou l’audio et sa transcription et une autre fenêtre de l’oscillogramme. Il permet ainsi de visionner une suite de clips et de les traiter. Mais il nécessite un système d’indexation de ces clips vidéo. Ce logiciel est payant (50$ pour les particuliers et 100$ pour les projets) contrairement à Transcriber qui est en téléchargement libre.
Transcriber est un logiciel de transcription de fichiers audio (musique, bruit et parole) . C’est en fait un outil d’assistance à la transcription manuelle du signal de la parole. Il est créé à partir du langage Tcl (Tool Command Language) et de l’extension du langage C par un groupe de plusieurs auteurs parmi lesquels figure Claude Barras. La partie supérieure de la fenêtre principale du logiciel contient l’éditeur de texte destiné à la transcription et la partie inférieure contient la ligne temporelle (timing) du fichier audio à transcrire. C’est un logiciel compatible avec plusieurs formats mais il ne prend pas en charge les fichiers vidéo. Il permet également de gérer les tours de parole dans une interaction en indiquant dès le début l’identité de chaque locuteur et d’esquisser une analyse acoustique (transcription fine). Un autre logiciel de transcription (TransICOR ) est dérivé du Transcriber et adapté à la convention de transcription ICO.
TRJS est « logiciel de transcription, d’édition et de visualisation de données et de corpus de langage oral » qui reprend les principales fonctionnalités de CLAN et de Transcriber. Il fonctionne sous Windows, Mac et Linux. Il est développé récemment par Christophe Parisse de l’Université Paris 10
EXAMARaLDA (Extensible Markup Language for Discours Annotation) est un logiciel de transcription et d’annotation des fichiers audio (wav, mp3) et vidéo développé par Thomas Schmidt et Kai Wörner en collaboration avec le centre de recherche sur le bilinguisme de l’université de Hamburg. Ce logiciel est conçu dans le cadre du projet intitulé « Méthodes computationelles pour la création et l’analyse de données multilingues ». Il présente, comme dans ELAN et Praat, une partition horizontale du texte de la transcription proportionnellement au déroulement du temps du fichier sonore audio ou vidéo. Il est librement disponible en téléchargement. Mais la lecture des fichiers audio et vidéo dans Exmaralda n’est pas satisfaisante, il ne lit que des séquences courtes. Le format natif de la transcription est XML associé à trois DTD. Son avantage est qu’il permet d’exporter des TextGrids. Aussi, peuvent être générés de façon verticale, des fichiers html, pdf et rtf représentant l’alignement entre le temps et les annotations. Mais il ne peut pas afficher les signes de l’API, l’importation des fichiers vers Praat et Anvil est impossible. C’est un logiciel en voie d’amélioration .
ANVIL est un logiciel de transcription multimodale qui utilise Quicktime comme lecteur intégré. Il est développé par Michael Kipp de l’université de la Saare en collaboration avec la DFKI (Deutsches Forschungszentrum für Kunstliche Intelligenz). En format d’entrée il prend en charge wav en audio et avi et mov en vidéo. Principalement utilisé pour la transcription des fichiers vidéo, ce logiciel permet d’afficher les transcriptions et l’alignement temporel des données sonores et visuelles. A Partir de sa commande Edit > specification> Change default specification Edit > Specification, on peut définir et hiérarchiser les spécifications de conventions d’annotations sous forme de fichier XML. Il est disponible en téléchargement après autorisation de l’auteur par E-mail . Il est spécialisé dans l’annotation des gestes et du langage des signes. Son inconvénient est qu’il ne prend pas en charge des vidéos de plus de 10mn. Aussi, le logiciel s’arrête souvent dès l’ouverture et ne permet pas l’impression et l’importation sous le format Word impliquant la mise en page .
Phon est un logiciel gratuit (open-source) développé grâce à la contribution d’individus, des organismes de recherche, des fonds, des centres de recherches et universités de plusieurs pays pour faciliter l’analyse des données phonologiques. Comme Praat, Phon est en complémentarité avec les autres logiciels de traitement des corpus oraux.
CLAN (Computerized Language Analysis) est un logiciel de transcription alignée de fichiers audio en format aif, aiff, wav, mp3 et vidéo en format mpeg, mpg, dat, mov. Il est développé par Brian MacWhinney et Leonid Spektor de l’université de Mellow Canergie. C’est un logiciel freeware qui fonctionne sur des plateformes Linux, Macintosh et Windows . Il est spécialisé dans la transcription de corpus multimédias, c’est-à-dire qu’il permet une transcription du signal audio et une annotation synchronisée d’événements, d’observations de gestes liés au signal vidéo. Ce qui permet de désambiguïser le signal audio et d’apporter plus de compréhension du contexte d’élocution. Il permet également l’exportation de fichiers vers d’autres logiciels comme Praat et ELAN. Malgré qu’il ne permette pas de lire plus d’un fichier vidéo à la fois, il a les avantages suivants :
1. La visualisation en temps réel de la transcription alignée et de la vidéo,
2. La formulation de requêtes particulières pour extraire des données ciblées,
3. Une augmentation à volonté des tiers intermédiaires précédées du signe %,
4. Une grande communauté d’utilisateurs qui ne cesse de s’accroître.
5. Une possibilité d’Importation et d’exportation de fichiers vers Praat.
6.
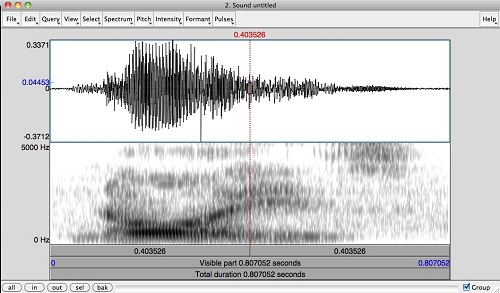
Praat est un logiciel développé par Paul Boersma et David Weenink à l’institut des Sciences Phonétiques de l’Université d’Amsterdam au Pays Bas pour la transcription et l’analyse acoustique et prosodique du signal de la parole. Plusieurs scripts (plugins) ont été créés pour le rendre plus performant. Ce sont EasyAlign, le prosogramme de Piet Mertens, le ProsoProm pour les syllabes proéminentes, le ProsoReport pour la description phonostylistique globale et les algorithmes MoMel-IntSint. Selon le tutoriel du linguiste Jean Philippe Goldman (2010) , « EasyAlign est un plugin (extension) de Praat qui permet de créer de manière semi‐automatique une annotation multi‐tires contenant une segmentation alignée en phonèmes, en syllabes, en mots et en énoncés, à partir d’un enregistrement de parole et d’une transcription orthographique de l’enregistrement ».
C’est un plugin qui génère et aligne semi automatiquement des annotations phonétiques à partir de la transcription orthographique ou phonétique d’énoncés. Le prosogramme de Piet Mertens permet le calcul des propriétés temporelles (débit, rythme et pauses) par la stylisation automatique à partir de la fréquence fondamentale F0, c’est-à-dire la segmentation du signal de la parole en noyaux syllabiques. Le format audio supporté est wav et mp3. Il est largement utilisé en analyse fine (syllabes, phonèmes). C’est un logiciel libre et open source utilisable sur les plateformes Macintosh, Linux et Windows. Le type de fichier qu’il utilise est le TextGrid. Ce TextGrid peut être exporté au format .eps et .emf pour des publications scientifiques ou imprimé à partir des scripts comme Ghostscript et GSView. L’alignement temporel entre le son, les graphiques et le texte est maintenu lors de l’exportation de fichiers de Praat à Anvil.
La spécificité de Praat fait qu’il n’est pas en concurrence par rapport aux autres logiciels, mais en complémentarité. Nous l’avons utilisé pour l’analyse phonétique et prosodique d’une langue africaine (le koromfe) dans le cadre de notre Master en informatisation des langues. Selon les théories linguistiques sur la syllabe, il existe plusieurs type de notation (transcription phonétique, sémantique, syntaxique, textuelle, prosodique), le prosogramme réalise alors une segmentation automatique et une transcription basée sur la perception indépendamment de ces théories souvent divergentes.
Pour réduire l’impact des micro-mouvements prosodiques sur la transcription du signal de la parole, le linguiste Daniel Hirst (2007) a développé un script à partir de Perl pour calculer automatiquement la valeur de la courbe intonative en Hertz. Ce script est jusqu’à présent le premier du genre et est nommé Momel –Intsint. Momel signifie Melodie modelisation et IntSint signifie INternational Transcription System for INTonation. Praat est un logiciel Multitâches permettant d’enregistrer le son, de le segmenter, le transcrire et l’annoter, l’analyser et de construire des grammaires dans le cadre de la théorie de l’optimalité (OT) et même écrire des scripts pour des tâches spécifiques.
WinPitch est un logiciel d’analyse muni des fonctions spécialisées pour la transcription, l’alignement et l’analyse des données prosodiques de corpus des fichiers multimédias. C’est un logiciel de transcription alignée développé dans le cadre du projet européen C-ORALCOM-2005. Il permet d’enregistrer le son et de voir en temps réel les courbes du signal de la parole, l’intensité le spectrogramme et la fréquence fondamentale. Il dispose de deux formats de sortie des données alignées ; un format en XML et un format en WP2, tous éditables. Il permet l’annotation de corpus, l’étude des phénomènes segmentaux et la formulation de requêtes contextuelles sur des données alignées. Winpitch reste cependant un logiciel payant disponible sous Windows.
Tous ces logiciels sont destinés à transcrire soit le son (audio), soit l’image (vidéo) ou les deux à la fois. Mais les possibilités qu’offrent ces logiciels ne sont pas les mêmes, elles dépendent des objectifs que se sont fixés les auteurs et les projets qui les développent. Il convient donc de faire le bon choix avant de commencer une transcription, il serait même judicieux de tenir compte du logiciel d’annotation et de transcription depuis l’enregistrement des données audio et vidéo. Aussi, la question du transfert ou de conversion de données des logiciels de transcription aux autres logiciels du traitement automatique des langues doit jouer dans ce choix. Parmi ces multiples logiciels nous pouvons citer ceux que nous connaissons mieux pour les avoir utilisés. Il s’agit de Nooj qui est un bon concordancier et qui permet de faire des grammaires locales, Toolbox et Flex destinés à la conception de dictionnaires et à la description des langues naturelles.
Pour le stockage, le partage et la fouille, des langages (xml) et des normes (TEI) sont proposés afin de faciliter les travaux à l’échelle communautaire et internationale.
La maîtrise du langage XML est recommandée pour les sciences du langage lorsque l’on veut aller plus loin dans le traitement des données, notamment dans le stockage et le partage. Il est aussi utilisé pour le balisage des données textuelles et donc des transcriptions. Il est plus simple que son ancêtre SGML. Le standard XML semble être le format le plus utilisé actuellement pour la structuration l’échange d’un système à un autre et la gestion des données. Le consortium w3 gère d’autres technologies de XML liées aux fonctions spécifiques. Il s’agit de Xpath destiné à l’identification et la navigation dans une arborescence XML, de Xlink et Xpointer servant à exprimer les liens, XSL pour définir les feuilles de styles (structure physique), de Xquery servant à faire des requêtes et du DOM servant d’interface pour la programmation.
La TEI (Text Encoding Initiative) qui signifierait en français « groupe d’initiative pour le balisage normalisé des textes » est une norme de codage et de balisage de texte afin de faciliter le stockage et le partage. Elle est issue d’un consensus de spécialistes de plusieurs domaines (littéraires, ethnologues, historiens, sociologues, linguistes, philosophes). Elle est devenue de nos jours un standard international et interdisciplinaire pour l’édition électronique en sciences humaines et qui prend en compte l’aspect multilingue. En plus des métadonnées de l’en-tête, du balisage de la forme des documents (la foliotation, abréviations utilisées, et tous les aspects formels de la transcription), elle permet le balisage de l’analyse voulue par le chercheur. La TEI intègre la création de documents basés sur le langage XML. C’est donc un outil complémentaire aussi bien pour ceux qui travaillent sur des corpus textuels que sur des corpus oraux.
Ce panorama d’outils informatiques est loin d’être exhaustif, mais à l’avantage de les vulgariser et de guider les novices dans leur méthodologie de recherche.
3. Comment choisir un logiciel en sciences du langage
Quand on est étudiant, il faut se référer à l’école doctorale à laquelle on appartient. Le choix d’un logiciel est fait en fonction de certaines options de recherche. Les recherches sont faites dans une sorte de collaboration entre des universités, centres de recherche et laboratoires. Et ces recherches prennent souvent en compte les améliorations de ces logiciels. La plupart des logiciels sont le fruit de collaboration entre chercheurs. Et des améliorations et mises à jour sont apportées au fur et à mesure des recherches afin de garder ces logiciels pertinents. Ces collaborations entre chercheurs vont souvent au-delà des clivages d’écoles et de ce fait, facilitent la recherche.
Dans le cadre des travaux de notre thèse, avions retenu principalement le logiciel CLAN pour la transcription de l’analyse de nos données pour plusieurs raisons ;
![]() Premièrement, ce logiciel est retenu de façon consensuelle pour le traitement des données collectées dans plusieurs pays au compte du projet « Transferts d’apprentissage ». Les conventions de nommage des séquences sont les mêmes, ce qui facilite l’exploitation et le partage des données entre les chercheurs de ce projet.
Premièrement, ce logiciel est retenu de façon consensuelle pour le traitement des données collectées dans plusieurs pays au compte du projet « Transferts d’apprentissage ». Les conventions de nommage des séquences sont les mêmes, ce qui facilite l’exploitation et le partage des données entre les chercheurs de ce projet.
![]() Deuxièmement, avant même notre inscription en thèse, nous avons bénéficié d’un stage de trois mois au laboratoire MoDyCo auprès de Christophe Parisse pour nous spécialiser dans sur cet outil au compte dudit projet. Ainsi avons-nous pu tester des codages théoriquement orientés.
Deuxièmement, avant même notre inscription en thèse, nous avons bénéficié d’un stage de trois mois au laboratoire MoDyCo auprès de Christophe Parisse pour nous spécialiser dans sur cet outil au compte dudit projet. Ainsi avons-nous pu tester des codages théoriquement orientés.
![]() Troisièmement, ce logiciel est mieux adapté que les autres sus cités pour remplir les besoins des recherches que nous menons sur le bilinguisme et plus particulièrement l’alternance codique dans le cadre de l’interaction en classe. Ceci parce que non seulement il permet de mieux traiter à la fois les fichiers audio et vidéo de grande taille, mais aussi et surtout parce que nous avions testé avec succès le codage du logiciel en fonction de notre orientation théorique.
Troisièmement, ce logiciel est mieux adapté que les autres sus cités pour remplir les besoins des recherches que nous menons sur le bilinguisme et plus particulièrement l’alternance codique dans le cadre de l’interaction en classe. Ceci parce que non seulement il permet de mieux traiter à la fois les fichiers audio et vidéo de grande taille, mais aussi et surtout parce que nous avions testé avec succès le codage du logiciel en fonction de notre orientation théorique.
![]() Quatrièmement, il y a une possibilité d’importation et d’exportation de données vers Praat. Ce qui nous permet, en cas de besoin, d’affiner l’analyse des difficultés de prononciation des élèves par l’analyse phonétique et acoustique de certains segments sonores.
Quatrièmement, il y a une possibilité d’importation et d’exportation de données vers Praat. Ce qui nous permet, en cas de besoin, d’affiner l’analyse des difficultés de prononciation des élèves par l’analyse phonétique et acoustique de certains segments sonores.
Tous ces éléments concourent à la pertinence du choix que nous avions fait, de transcrire avec CLAN nos données primaires collectées dans un contexte bilingue au Burkina Faso. « De manière idéale, le choix d’un système de transcription ne devrait être fait que sur des critères d’efficacité ou de besoin de la recherche » (Parisse, Morgenstern, & others, 2010, p. 211).
Conclusion
On peut retenir que les outils informatiques pour les sciences du langage sont de deux types. Ceux qui sont utilisé pour la recherche basé sur les données textuelles et ceux qui sont utilisés dans le traitement des corpus oraux, voire multimédias. Nous avons essayé d’en énumérer quelques-uns à titre illustratif pour chaque type. Le langage XML tout comme la norme de balisage TEI sus-évoqués, sont utiles, quels que soient les domaines de recherche. Et de toutes les façons, l’oral ou l’audio-visuel acquièrent une part de textuel après la phase de transcription. Pour le choix, il faut noter que la pertinence d’un outil de recherche dépend de l’encadrement que l’on reçoit, de l’université, de l’école doctorale ou de l’équipe de recherche auquel l’on appartient. La réussite du travail de recherche dépend donc de la prise en compte de tous ces paramètres.
Indication bibliographique
Blanche-Benveniste, Claire (2000). La transcription de l’oral et morphologie. Romania una diversa, 1, pp. 61–74.
CETRO, Rosa (2011). « Outils de traitement des langues et corpus spécialisés : l’exemple d’Unitex ». Cahier de recherche de l’école doctorale en linguistique française, n°5, pp 49-63. https://hal.archives-ouvertes.fr/hal-00762794
GUIRE, Inoussa (2007). Les emprunts du koromfe, variante de Mengao, Mémoire de maîtrise, université de ouagadougou, 80 p.
GUIRE, Inoussa (2012). Esquisse de constitution de corpus oraux de la langue koromfe, variante d’Aribinda,Mémoire de Master 2, Université de Nantes, 65 p.
GUIRE, Inoussa (2015), Alternances de codes entre L1-fulfulde et L2-français dans l’enseignement bilingue au Burkina-Faso : des technologies d’analyse linguistique de corpus oraux aux problématiques didactiques, Thèse de Doctorat, Paris 10, 447 p. https://tel.archives-ouvertes.fr/tel-01312448
Parisse, C., Morgenstern, A., (2010). Transcrire et analyser les corpus d’interactions adulte-enfant. In Edy Veneziano, A. Salazaz Orvig, J.Bernicot (édts). Acquisition du langage et interaction. Paris : L’harmattan pp. 201–222.
Inoussa GUIRE
Vos commentaires
1. Le 10 janvier 2018 à 15:00, par Colosse En réponse à : Outils informatiques pour les sciences du langage, comment en choisir un ?
Je m’incline respectueusement devant votre érudition, cher monsieur ! Je crois cependant que ce n’est pas vraiment l’endroit pour de tels écrits...qui se lisent difficilement : ce n’est pas vraiment le genre d’article à publier sur des forums web. Juste un avis
2. Le 10 janvier 2018 à 16:45, par TANGA En réponse à : Outils informatiques pour les sciences du langage, comment en choisir un ?
Monsieur GUIRE,
Serait ce facile pour vous de faire un enregistrement de dires, puis changer la voix du diseur (celui qui a parlé) par celle d’une autre personne ?
Comme cela, les coupés collé des bandes magnétiques vont diminuer ou finir (on a vu avec les parole du lion). Et puis, on pourra dire quelque chose puis mettre ça sur quelqu’un d’autre.
Le 17 janvier 2018 à 12:33, par Guiré Inoussa En réponse à : Outils informatiques pour les sciences du langage, comment en choisir un ?
Ok, monsieur Tanga votre remarque est pertinente dans la mesure où n’importe qui peut faire ce que vous dites. Mais au niveau éthique le montage d’un enregistrement de toutes pièces semble relever du faux et de l’usage du faux. Si on fait cela, non seulement ça ne passera nul part parce que c’est facile à détecter souvent même pour le profane, mais aussi et surtout on ternit son image pour de bon dans le domaine de la recherche. Il faut toujours partir des données empiriques, suivre une démarche explicite,etc. Voyez -vous un peu de quoi je parle ? Merci quand même
3. Le 10 janvier 2018 à 18:24, par Traitement de Signal En réponse à : Outils informatiques pour les sciences du langage, comment en choisir un ?
Bonjour Mr Guire,
Bon recap , Est ce que ces outils sont adaptes a nos langues locales ? Autrement dit font -il la transcription du Moore , Dioula etc... Sinon ca serai pertinent d"orienter vos recherches vers cette direction si ce n’est pas fait . L’idee derriere c’est de pouvoir integrer nos langues dans les logiciels , avoir un clavier en Moore ou Dioula , Peulh etc . Nous n"arretons pas de mimer l"occident oubliant nos potentialites locales , sources de levier de developpement.
Tu peux me contacter au abdou.sawadogo@gmail.com pour plus d"infos.
Merci
Abdou Sawadogo
Montreal
4. Le 11 janvier 2018 à 04:19, par Zimm En réponse à : Outils informatiques pour les sciences du langage, comment en choisir un ?
Internaute 1 : Si Guiré arrive a bien traduire son texte en Anglais (par exemple), en y intégrant ses résultats de recherche il peut très bien le publier dans un journal de Linguistique-Informatique (Computational Linguistics). C’est un domaine actif de recherche multi et pluri-disciplinaire qui fait intervenir les mathématiques, l’informatique, la linguistique théorique avec des applications pratiques en robotique, intelligence artificielle, les neurosciences, etc...
Tous mes encouragements à lui...
Le 17 janvier 2018 à 11:51, par Guiré Inoussa En réponse à : Outils informatiques pour les sciences du langage, comment en choisir un ?
Ok, merci pour cet apport. Je vais essayer de contacter ce journal en y intégrant quelques résultats.
Merci monsieur Zimm